












As part of this year’s internship at Fingoweb, we are working on an AI project where our interns are facing the challenges of implementing a language model and building a solution from scratch. Read about how we selected the model, cleaned the data, and the challenges we encountered.
In this article, you will find:
- The process of implementing the AI project.
- Hardware limitations and model selection.
- Equipment selection.
- Data preparation.
- Next steps.
The AI boom in late 2022 demonstrated that even non-technical individuals can have a keen interest in complex technology. While AI solutions have been around for years, the availability of the OpenAI language model has made AI more accessible to the public.
The AI boom in late 2022 demonstrated that even non-technical individuals can have a keen interest in complex technology. While AI solutions have been around for years, the availability of the OpenAI language model has made AI more accessible to the public.
Internship at Fingoweb
We aim to share knowledge and expertise with students, collaborating to cultivate the next generation of exceptional Polish IT specialists. This led us to conceive an internship program that will unite the most outstanding candidates around an intriguing project.
We sought ambitious and eager-to-learn students who desire more than just fetching coffee during their internship. Instead, we presented them with a substantial task:
Developing a virtual assistant using an open-source AI model that will assist customers of a shopping gallery in locating stores and products.
The project is driven by two primary objectives:
- Constructing a solution based on an open-source LLM.
- Gaining a comprehensive understanding of the functionality of LLM and genAI.
Naturally, our interns receive support from experienced specialists employed at Fingoweb, as well as guidance from their mentors.
AI Project Implementation Process
The first step of the project is to create a simple classifier that answers questions about products in a shopping gallery. The model should handle basic questions like:
Q: Where can I buy a hoodie?
A: At the Cropp store.
If the model works correctly in its basic form, it will be expanded to answer more complex questions like: Where can I buy a hat for 100 PLN for a child? Where can I buy a hat, a t-shirt, and socks?
But that’s not all. The next stage could involve introducing a Seq2Seq solution to answer complex questions with broader context, such as: Can I enter the gallery with a dog without a muzzle?
Hardware Limitations and Model Selection
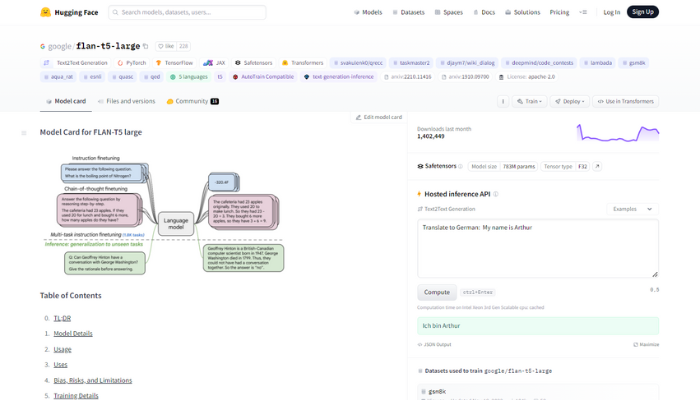
Considering the project requirements and the need for a simple classifier in the initial stage, it was crucial to choose the right model. Here, Hugging Face comes to the rescue – a community of AI specialists.
The model must meet certain requirements. It has to be:
- Open source with commercial use possibility.
- Written by a well-known organization.
- Relatively lightweight to minimize hardware load.
After analysis, the team decided to use flan-t5-large. It is a popular model provided by Google. Its small size (783 million parameters) allows for efficient processing without significant hardware burden. Another advantage of this text-to-text model is its immense popularity – it has been downloaded over 1.3 million times in the last month alone.
The model we are currently working on is flan-t5-large. We decided on it because of its small size, which allows us to train and test new mechanics relatively quickly. It is quite possible that a model of this size will be sufficient to handle the classification problem.
– adds Kuba, this year’s intern.
Hardware
After selecting the model, one of the first issues was hardware limitations. Training language models requires computational resources, specifically graphics cards with sufficient VRAM.
Our interns use two independent workstations – one for data preparation and testing, and another for model training. The latter is equipped with two RTX 3090 cards, which are connected by NVLink and allow loading models up to 60B (60 billion parameters). However, a model like flan-5-large can easily be trained on a single RTX 3090 card with 24 GB VRAM.
The choice of a less demanding hardware model was intentional: this allows the team to quickly test and make changes.
Data
“Data is the new oil” – such a statement can be found online recently. And fundamentally, it is true. It would be worth adding that high-quality data is the most valuable. Regardless of how the model is trained, the principle remains the same: the better the data, the higher the effectiveness.
Data is the most complex issue in the model training process. They must be prepared and anticipate various possible questions asked by the client. The worse the quality of the data, the worse the results of the model. On the other hand, the more data, the better the trained model.
– comments Kuba.
The solution designed by the interns is intended to help find stores based on the types of products they offer. For this reason, in addition to the list of products that needed to be categorized, questions that will be asked by assistant users were also needed.
In the first place, the team manually created product categories and assigned them to the stores where they appear. The next step was to create questions. Instead of writing 120,000 questions manually, they were automatically generated using GPT (synthetic data).
This solution also has its drawbacks. ChatGPT is not a tool designed to generate datasets, and usually the data it generates needs cleaning. Nevertheless, in the team’s opinion, it is the most efficient way to train the model.
Next Steps
Projects carried out as part of internships consist of 3 teams of 2 interns each. You will learn more about the larger number of projects carried out within Fingoweb internships in the next articles.
About Fingoweb
We are a software house based in Kraków, and we help businesses stand out online by building custom solutions. Fingoweb consists of over 50 experts who specialize in creating modern tailor-made applications and systems. We build web applications, create necessary documentation, and design professional UI/UX.



