












Podczas realizowania projektów opartych o AI, warto mieć podstawową wiedzę na temat kilku pojęć związanych z budowaniem tego typu rozwiązań. Wiedza ta pomoże w komunikacji z podwykonawcą i zrozumieniem własnych potrzeb. Na warsztat bierzemy bazy wektorowe, nierozłącznie kojarzące się ze sztuczną inteligencją.
Spis treści:
- Po co nam wektor?
- Jak tworzy się wektorową bazę danych?
- Czym są bazy wektorowe?
Jeśli spotkałeś/aś się ze sformułowaniami baza wektorowa, vector embeddings, Pinecone i chcesz dowiedzieć się, o co w tym tak naprawdę chodzi — świetnie się składa. Wprawdzie tworzenie projektów opartych o nauczanie maszynowe nie wymaga stosowania baz wektorowych, te popularne są przede wszystkim w LLM-ach (Large Language Model), to sformułowanie na tyle często pojawia się w mediach, że warto je zbadać.
Warto pamiętać tylko, że u podstaw każdego projektu machine learning powinny stać przede wszystkim cele biznesowe oraz dane, na których pracujemy. Przed podjęciem decyzji o stworzeniu bazy, warto zastanowić się, czy jest ona niezbędna do realizacji danego projektu.
Same bazy wektorowe to ciekawy i rozbudowany temat, który poniżej przedstawiony jest w uproszczonej, lekkostrawnej wersji.
Po co nam wektor?
U podstaw każdego projektu AI znajdują się dane. Im lepsze są dane, tym wyższa staje się skuteczność rozwiązania, a sformułowanie 'data is the new oil’ nie pochodzi znikąd. Osoby związane z technologią na pewno spotkały się z tabelami SQL, danymi segregowanymi hierarchicznie czy obiektowo.

Tradycyjne metody wyszukiwania informacji (np. string search) polegają na sprawdzeniu, czy wyszukiwany element znajduje się w bazie danych. Ograniczeniem będzie fakt, że jeśli nie wyszukujesz konkretnego elementu, to tradycyjna baza danych będzie ograniczona.
Wektorowe bazy pozwalają wyszukiwać na podstawie semantycznej bliskości data pointów, a wektorowa reprezentacja danej może posiadać dużą liczbę cech. Z tego powodu są tak popularne w rozwiązaniach ML i AI
Tworzenie wektorów z danych, czyli tzw. embedowanie, o którym poniżej, to proces, który daje możliwość przeniesienia semantycznej zależności do świata liczb. Z wektorowymi bazami danych spotykasz się regularnie… korzystając z wyszukiwarki Google, czy systemów rekomendacji w sklepach internetowych.
Żeby nieco pobudzić wyobraźnię:
- Wyobraź sobie dwuwymiarową przestrzeń w formie wykresu z osią X i Y.
- Na przestrzeń nałożone są twoje dane. Ustalmy, że jest to 10 data pointów, jak z wykresu poniżej.
- Każda dana posiada odpowiednią liczbę na osi X i Y, czyli dwuwymiarowy wektor.
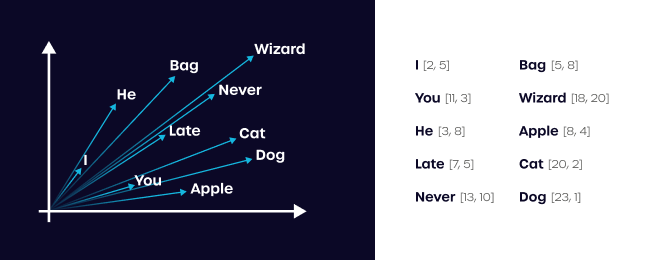
Zadanie przypisywania liczbowej wartości cechy do danych nazywane jest właśnie embedowaniem. To, co jednak jest najciekawsze, to fakt, że dane opisywane przez sieci neuronowe mają wielokrotnie wyższą liczbę „wymiarów”, mogącą sięgać nawet 2000. A relacja pomiędzy data pointami może być określana w formie odległości.
Przykładowo, najbliżej słowa kot z poniżej grupy będzie (kiedy 1 = to samo słowo):
- pies 0.8
- lis 0.75
- wiewiórka 0.5
- kura 0.2
Na podstawie informacji o semantycznej bliskości wektorów, modele AI/ML mogą tworzyć odpowiedzi na zapytania.
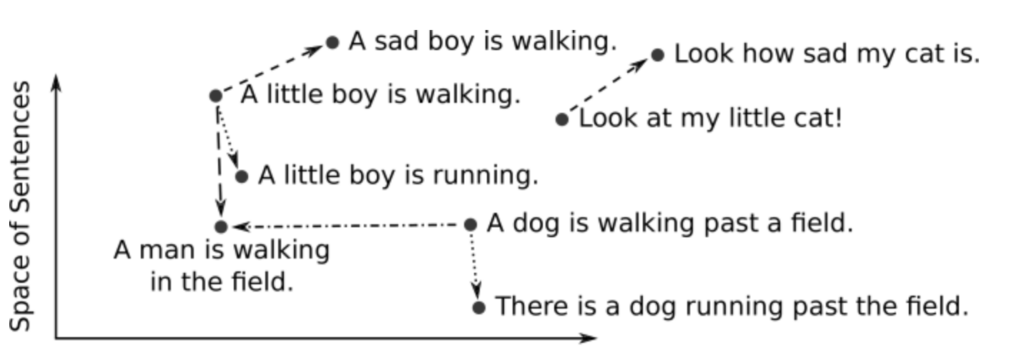
Na takiej zasadzie działają wszystkie rozwiązania zwłaszcza oparte o tekst, które odpowiadają na twoje pytanie poprzez znalezienie semantycznej bliskości w bazie danych.
Jak tworzy się wektorową bazę danych? Vector embedding
Proces zmieniania danych na wektory nazywa się embedowaniem (vector embedding) i można go wykonać na kilka sposobów, w zależności od potrzeb. W teorii możesz wykorzystać specjalistę z danej branży.
Załóżmy, że mamy do przygotowania bazę zdjęć motocykli i angażujemy specjalistę z branży motocyklowej, który będzie brał udział w ich opisywaniu. Zaprojektuje serię cech, np. typ motocykla, wielkość kół, owiewka lub jej brak, marka. Na tej podstawie powstanie baza, w której marka „Ducati” (włoskie motocykle sportowe), będzie bliżej z „motocykle sportowe”, niż np. Harley-Davidson, który takich motocykli w ofercie nie ma.
Problem z takim rozwiązaniem – ogromny koszt finansowy i czasowy, zwłaszcza przy większych data setach. Z tego powodu często wykorzystuje się gotowe rozwiązania, a dokładniej sieci neuronowe.
Wektory to matematyczna reprezentacje danych, które mają ułatwiać pracę, a nie ją utrudniać. Konieczne jest ocenienie, czy tworzenie bazy wektorowej będzie niezbędne do projektu i ma podstawy biznesowe.
I tutaj kolejne opcje: tworzenie własnego modelu do generowania danych lub skorzystanie z gotowych. Nie da się ukryć, że dedykowane tworzeniu wektorów sieci neuronowe posiadają wysoką skuteczność i wielu przypadkach na rynku istnieją gotowe rozwiązania do tworzenia wektorów dla określonych typów danych (np. BERT dla tekstu, sieci CNN dla zdjęć).
Jeśli nadal jesteś zainteresowany/a, to zerknij koniecznie na poniższe wideo, gdzie omawiane jest embedowanie tekstu dla rozwiązań NLP (Natural Language Processing):
Czy w 2026 roku nadal warto inwestować w bazy wektorowe?
Choć bazy wektorowe zyskały ogromną popularność w ostatnich latach, w 2026 roku coraz więcej firm zastanawia się, czy nadal są niezbędne. W tym rozdziale przyjrzymy się, kiedy ich użycie ma sens, a kiedy lepiej postawić na inne podejścia.
Odpowiedź zależy od rodzaju projektu. Jeśli budujesz rozwiązanie oparte o duże modele językowe (LLM), przetwarzasz dużo niestrukturyzowanych danych (np. dokumenty, rozmowy, obrazy), to baza wektorowa nadal będzie bardzo przydatna. Umożliwia szybkie i trafne dopasowanie wyników – a to bezpośrednio przekłada się na jakość działania systemu.
Ale jeśli Twój projekt opiera się głównie na strukturach tabelarycznych, danych liczbowych lub klasycznym filtrowaniu informacji, możesz z powodzeniem korzystać z relacyjnych baz danych lub rozwiązań hybrydowych.
W 2026 roku coraz więcej narzędzi i frameworków łączy różne typy baz danych – i to jest kierunek, który warto obserwować. Wybór nie powinien zależeć od mody, ale od celu biznesowego i rodzaju danych, jakimi dysponujesz.
Czym są bazy wektorowe?
Jak nietrudno się domyślić, bazy wektorowe wykorzystywane są do przechowywania… wektorów. Tego typu dane są bardzo przydatne przy pracy z przetwarzaniem języka naturalnego (NLP), modelami rekomendacyjnymi i przy semantycznym wyszukiwaniu.
Mają też inne plusy:
- Efektywne przetwarzanie danych. Mogą szybko przetwarzać duże ilości danych. Wynika to z metody nazywanej „wektoryzacją”, która pozwala im wykonywać operacje na całych zestawach danych naraz, a nie na pojedynczych elementach.
- Wysoka wydajność. Ze względu na swoją konstrukcję, wektorowe bazy danych zapewniają wysoką wydajność. Mogą obsługiwać skomplikowane zapytania i obliczenia szybciej niż tradycyjne bazy danych.
- Skalowalność. Mogą łatwo obsługiwać rosnące ilości danych, bez znacznego spadku wydajności.
Na rynku dostępne są gotowe bazy, w tym na przykład Pinecone, Weaviate, albo opensource'owy Chroma.

Możliwości nie mają końca
Bazy wektorowe przydatne są, gdy będziecie budować wewnątrzfirmowego chatbota czy system rekomendacji dla swoich klientów.
Do zrealizowania projektu opartego o AI potrzebne są dobrej jakości dane, pomysł, cel biznesowy i niewielka grupa specjalistów. Oferta rozwiązań opensource, dedykowanych rozwiązań płatnych oraz tych w ramach frameworków od technologicznych gigantów (np. Vertex AI od Google), pozwala na bardzo skuteczne realizowanie projektu,

Najczęściej zadawane pytania - bazy wektorowe
Co to są bazy wektorowe i jakie mają zastosowanie?
Bazy wektorowe to specjalistyczne bazy danych, wykorzystywane głównie w przetwarzaniu języka naturalnego (NLP), modelach rekomendacyjnych i semantycznym wyszukiwaniu. Przechowują one wektory, czyli matematyczne reprezentacje danych, które ułatwiają szybkie przetwarzanie dużych ilości informacji.
Jak tworzy się bazy wektorowe?
Tworzenie wektorowej bazy danych, znane jako proces embedowania (vector embedding), może być realizowane na różne sposoby w zależności od potrzeb. Można zaangażować specjalistów do ręcznego projektowania cech danych lub wykorzystać gotowe rozwiązania i sieci neuronowe, które automatycznie generują wektory na podstawie danych.
Dlaczego wektory są ważne w projektach AI?
Wektory są kluczowe w AI, ponieważ pozwalają na efektywne i szybkie przetwarzanie dużych ilości danych. Umożliwiają semantyczne wyszukiwanie oraz analizę danych, co jest szczególnie przydatne w rozwiązaniach opartych o NLP i modelach rekomendacyjnych. Wektory pozwalają na przekształcenie złożonych danych w formę, którą łatwiej jest analizować i przetwarzać przez modele AI.


