












Sztuczna inteligencja rozwija się w zawrotnym tempie, a rozwiązania oparte na dużych modelach językowych (LLM), takie jak ChatGPT czy Claude, stają się coraz bardziej popularne w biznesie. Mimo to, wiele firm wciąż boryka się z jednym podstawowym problemem – jak sprawić, by modele te korzystały z aktualnych, wiarygodnych danych, zamiast halucynować odpowiedzi? Odpowiedzią na to wyzwanie jest RAG, czyli Retrieval-Augmented Generation – podejście, które pozwala łączyć możliwości generatywnej AI z bazami wiedzy dopasowanymi do konkretnych potrzeb.
RAG znajduje zastosowanie m.in. w chatbotach, systemach wspierających pracę z dokumentami, analizie danych i automatyzacji obsługi klienta. Dzięki niemu możliwe jest tworzenie rozwiązań, które są nie tylko bardziej precyzyjne, ale też lepiej dostosowane do kontekstu biznesowego. Jak dokładnie działa Retrieval-Augmented Generation, jakie technologie za nim stoją i kiedy warto go zastosować? W tym artykule znajdziesz praktyczne wyjaśnienie i przykłady wykorzystania tej przełomowej metody.
Czym jest Retrieval-Augmented Generation i jak działa?
Retrieval-Augmented Generation (RAG) to nowoczesne podejście w dziedzinie sztucznej inteligencji, które łączy możliwości zaawansowanego modelu językowego z dostępem do zewnętrznych baz wiedzy. Dzięki temu połączeniu RAG AI jest w stanie generować bardziej trafne i kontekstualne odpowiedzi na zadawane pytania.
Połączenie modelu językowego z bazą wiedzy
RAG łączy dwa kluczowe elementy: model językowy, który odpowiada za generowanie tekstu, oraz system wyszukiwania, który przeszukuje rozległe zbiory danych, aby znaleźć trafne informacje. Dzięki temu możliwe jest wzbogacenie odpowiedzi o aktualne, wiarygodne treści, co zwiększa ich precyzję i użyteczność.
Najważniejsze komponenty tego podejścia to:
- model językowy (np. GPT), odpowiedzialny za tworzenie spójnej odpowiedzi,
- system wyszukiwania (retriever), który znajduje najbardziej relewantne fragmenty z bazy wiedzy,
- zewnętrzne źródło wiedzy, np. dokumenty firmowe, bazy danych, pliki PDF, artykuły,
- mechanizm łączenia wyszukanej wiedzy z promptem, przekazywanym do modelu.
W efekcie użytkownik otrzymuje odpowiedź, która nie tylko brzmi naturalnie, ale też jest osadzona w kontekście aktualnych i konkretnych danych.
Proces generowania odpowiedzi krok po kroku
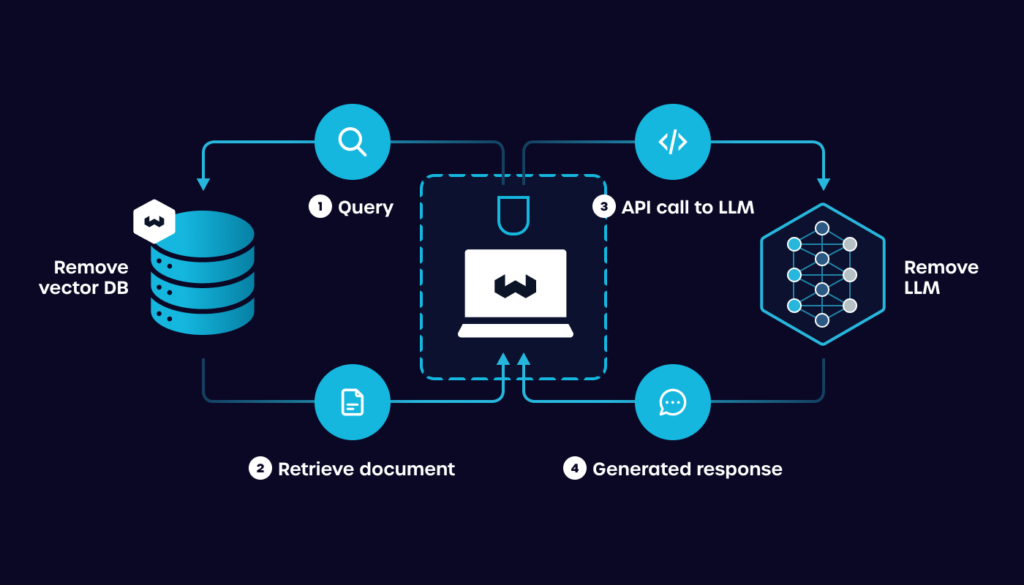
Aby połączyć zalety aktualnych danych z możliwościami dużych modeli językowych, RAG AI wykorzystuje precyzyjnie zaprojektowany ciąg operacji. Dzięki temu możliwe jest tworzenie odpowiedzi, które nie tylko są poprawne językowo, ale również trafnie osadzone w kontekście wiedzy zewnętrznej. Poniżej przedstawiamy techniczny przebieg działania systemu:
- Otrzymanie zapytania użytkownika
Użytkownik wprowadza pytanie lub polecenie, które trafia do systemu RAG jako tekst wejściowy. - Konwersja zapytania do postaci wektorowej
Tekst zapytania jest przekształcany na embedding (wektor liczbowy), który umożliwia jego porównanie z innymi dokumentami w przestrzeni semantycznej. - Wyszukiwanie kontekstowych dokumentów
Retriever przeszukuje zewnętrzną bazę wiedzy (np. indeksy wektorowe, dokumenty firmowe) w celu znalezienia najbardziej relewantnych fragmentów powiązanych z treścią zapytania. - Wybranie top-N dokumentów
System wybiera kilka najlepiej dopasowanych wyników (np. top-3 lub top-5), które następnie zostaną użyte jako kontekst wejściowy dla modelu językowego. - Połączenie kontekstu z promptem
Wybrane fragmenty są łączone z oryginalnym zapytaniem i przekazywane jako pełen prompt do modelu językowego. - Generowanie odpowiedzi przez LLM
Model językowy analizuje dostarczony kontekst i generuje końcową odpowiedź, integrując informacje z bazy wiedzy z własną strukturą językową. - Zwrócenie odpowiedzi użytkownikowi
Ostateczna odpowiedź, spójna językowo i oparta na rzeczywistych danych, zostaje przekazana użytkownikowi.
Dzięki takiej architekturze RAG łączy najlepsze cechy wyszukiwania informacji i generatywnej AI – zapewniając odpowiedzi, które są zarówno aktualne, jak i angażujące. Takie podejście minimalizuje halucynacje, zwiększa precyzję i pozwala modelowi dostosować się do dowolnego, nawet bardzo specjalistycznego kontekstu.
Dlaczego RAG rewolucjonizuje sztuczną inteligencję?
RAG rewolucjonizuje sztuczną inteligencję dzięki eliminacji problemu halucynacji w generacji tekstu oraz umożliwieniu dostępu do aktualnych informacji, które mogą być kluczowe w wielu zastosowaniach. To przełomowe podejście otwiera nowe możliwości w dziedzinie przetwarzania języka naturalnego i zastosowania sztucznej inteligencji w realnym świecie.
Eliminacja halucynacji i dostęp do aktualnych informacji
Tradycyjne modele językowe (LLM), działające wyłącznie na podstawie wytrenowanych danych, mają ograniczoną wiedzę, zamrożoną w momencie treningu. W rezultacie często dochodzi do tzw. halucynacji – generowania odpowiedzi, które brzmią wiarygodnie, ale są niezgodne z faktami.
RAG rozwiązuje ten problem poprzez integrację modelu generatywnego z zewnętrzną bazą wiedzy, co umożliwia dynamiczne pozyskiwanie danych w czasie rzeczywistym. Zamiast polegać wyłącznie na parametrach modelu, system wykorzystuje wyszukiwarkę dokumentów, która dostarcza zweryfikowane i aktualne informacje do promptu wejściowego.
Główne elementy eliminujące halucynacje:
- retriever przeszukuje aktualne i kontrolowane źródła wiedzy (np. wektorowe bazy danych),
- model językowy generuje odpowiedź tylko w oparciu o dostarczony kontekst, a nie własne „zgadywanie”,
- proces retrieval-augmented prompting umożliwia pełną transparentność – wiadomo, z jakich dokumentów pochodzą dane.
Dzięki temu RAG może być wykorzystywany w zastosowaniach wymagających wysokiej precyzji i zgodności z faktami – takich jak obsługa klienta, dokumentacja techniczna, medycyna czy prawo.
Wiedza specjalistyczna bez retrenowania modelu
RAG umożliwia wykorzystanie wiedzy domenowej bez konieczności kosztownego i czasochłonnego retrenowania modelu językowego. Dzięki zastosowaniu retrievera, system może dynamicznie pobierać informacje ze specjalistycznych źródeł – takich jak dokumentacja techniczna, publikacje naukowe czy bazy przepisów prawnych. Wystarczy zaktualizować zawartość bazy wiedzy, aby model automatycznie zaczął uwzględniać nowe informacje w generowanych odpowiedziach.
Proces ten nie wymaga ingerencji w strukturę ani parametry modelu, co znacząco upraszcza utrzymanie systemu. Takie podejście zapewnia wysoką elastyczność i umożliwia szybkie dostosowanie do zmieniającego się otoczenia informacyjnego. W efekcie RAG doskonale sprawdza się w środowiskach, gdzie liczy się aktualność i precyzja wiedzy – np. w medycynie, prawie czy branżach regulowanych.

Zastosowania RAG w praktyce
Zastosowania RAG w praktyce obejmują różnorodne obszary, które wspierają zarówno wewnętrzne operacje, jak i zewnętrzne interakcje z klientami. Dzięki elastyczności tej technologii, wiele branż zaadaptowało RAG w swoich procesach w celu poprawy efektywności i jakości świadczonych usług.
Wewnętrzne narzędzia wspierające zespoły
RAG umożliwia budowę wewnętrznych aplikacji knowledge‑workerowych, które automatycznie odpowiadają na typowe pytania, dostarczają statusy projektów lub wspierają analizę dokumentów — wszystko bez ręcznego wyszukiwania. Dzięki temu zespoły szybciej znajdą potrzebne informacje i mogą skupić się na zadaniach strategicznych.
Przykład z McKinsey pokazuje skuteczność takiego podejścia: ich wewnętrzny system RAG‑owy nazwany Lilli wykorzystuje 100 000+ dokumentów i odpowiada na około 500 000 zapytań miesięcznie, co przełożyło się na około 30% oszczędność czasu poświęcanego na wyszukiwanie informacji.
W efekcie, RAG wspiera organizacje w tworzeniu inteligentnych narzędzi wewnętrznych, które realnie zwiększają produktywność, redukują czas wyszukiwania i poprawiają zadowolenie pracowników.

Produkty i aplikacje końcowe
RAG znajduje szerokie zastosowanie w gotowych produktach i usługach, w których liczy się dostęp do aktualnych danych, personalizacja treści oraz szybkość reakcji systemu. Dzięki połączeniu komponentu wyszukiwania z generatywną AI, aplikacje końcowe mogą dostarczać trafne, kontekstowe odpowiedzi w czasie rzeczywistym – co przekłada się na wyższą jakość doświadczeń użytkownika.
Przykładowe zastosowania RAG w aplikacjach produkcyjnych:
- Chatboty e-commerce – dostarczają szczegółowych informacji o produktach (dostępność, parametry techniczne, opinie), bazując na aktualnych danych z bazy produktów.
- Asystenci wirtualni – odpowiadają na pytania klientów w oparciu o dokumentację techniczną, warunki umów lub instrukcje obsługi.
- Systemy rekomendacji – sugerują produkty lub treści, wykorzystując dane historyczne użytkownika oraz kontekst z zewnętrznych źródeł (np. nowości branżowe).
- Helpdesk AI – automatyzują obsługę zgłoszeń, odczytując zgłoszenia użytkowników i odpowiadając na nie w oparciu o bazę wiedzy firmy.
- Portale wiedzy dla klientów B2B – udostępniają interaktywną pomoc, w której klient może zadawać pytania dotyczące oferty, integracji czy SLA.
Wdrożenie RAG w tego typu produktach pozwala firmom nie tylko poprawić jakość obsługi klienta, ale także zautomatyzować procesy, zwiększyć konwersję i lepiej skalować swoje działania.

FAQ: RAG
Co to jest RAG w sztucznej inteligencji?
RAG, czyli Retrieval-Augmented Generation, to technologia sztucznej inteligencji, która łączy generowanie tekstu z wyszukiwaniem zewnętrznych źródeł informacji. Dzięki temu modeli językowe mogą dostarczać dokładniejsze i bardziej aktualne odpowiedzi.
Jak działa Retrieval-Augmented Generation?
Retrieval-Augmented Generation:
- Przyjmuje zapytanie użytkownika.
- Wyszukuje powiązane dokumenty w zewnętrznej bazie wiedzy.
- Łączy znalezione informacje z promptem.
- Przekazuje całość do modelu językowego.
- Model generuje odpowiedź opartą na faktach z dokumentów.
Czym RAG różni się od klasycznego modelu językowego?
RAG różni się od tradycyjnych modeli językowych tym, że łączy generację tekstu z dostępem do aktualnych baz wiedzy, co eliminuje problem halucynacji. Klasyczne modele często opierają się wyłącznie na danych, na których były trenowane, co może prowadzić do nieaktualnych informacji.
Jakie są zalety stosowania RAG?
RAG oferuje szereg korzyści, które sprawiają, że jest idealnym rozwiązaniem dla systemów wymagających precyzyjnych i kontekstowych odpowiedzi:
- dostęp do aktualnych informacji bez retrenowania modelu,
- zwiększona precyzja odpowiedzi dzięki oparciu na realnych danych,
- możliwość integracji wiedzy specjalistycznej z własnych źródeł,
- redukcja halucynacji generowanych treści,
- lepsza personalizacja odpowiedzi,
- łatwiejsze utrzymanie i aktualizacja systemu.
W jakich branżach warto wdrożyć RAG?
RAG można wdrożyć w wielu branżach, w tym w e-commerce, medycynie, edukacji czy finansach. Jego elastyczność sprawia, że jest użyteczny w środowiskach wymagających szybkiej i precyzyjnej obsługi informacji.


